Overview of imsi
Role of imsi in climate model simulations
imsi is first and foremost a configuration tool written in python3, although it does also provide
additional infrastructure.
The overaching challenge that imsi is designed to tackle is the requirement to support dozens of model configurations and hundreds of experiment configurations across tens of compute platforms for science applications. The configurations require different model settings at compile and runtimes, have different input files, output files and diagnostics, and require a unique environment to function on each individual machine.
Overall, there and many thousands upon thousands of configuration parameters, variables, swithes and settings, such that manual configuration is impossible. In fact, there is so much configuration information, that organization is key. The problem is not well posed for the historical methods of shell scripting and variables.
Imsi provides a conceptual framework for organizing model configuration information in a highly organized, machine parseable way, the enables inheritance and minimizes duplication. The tools within imsi parse this configuration information, and output a series of downstream files that provide all the required information for the downstream scripting and model run.
Therefore, imsi takes user choices of model selection, experiment selection, machine selection, and other options, and ensures that the ultimate resulting model simulation obtains all the required information. Imsi is not primarily a sequencer, or even sequencing scripting. However, by capturing and applying literally all model configuration, imsi massively simplifies downstream sequencing scripts.
imsi design principles and goals
Enable flexible configuration across many models, experiments and user options
Improve the management of configuration information, through logically organized data structures and transparent data flows
Reduce duplication (DRY), potential for human error, and enable programatic parseabilty of configuration data
Be robust, portable, maintainable
Apply purely generic operations common to any modelling system, without any knowledge of the specific underlying model/experiment/machine.
How imsi works
imsi itself is a python tool which parses configuration information that is largely supplied by an imsi-enable model. Together with user sepecified selections, imsi parses the configuration, and writes output files that are used downstream in compilation and model sequencing.
Users intract with imsi via the CLI: imsi.cli. Imsi writes state files, so that subsequent calls to imsi have full knowledge
of the previous state - which is to say, imsi has a type of memory that allows it to logically operate in a consistent way across
separate calls to the program.
imsi data structures (hierachical configuration format)
One of the most important parts about imsi is the configuration data model. The imsi python code itself has no knowledge of any
specific configuration information, only about generic configuration operations. All configuration information is contained in
a series of logically organized yaml files, within the imsi_config directory, which must be found at the top directory level
of any imsi enable model (e.g. CanESM imsi_config
. These yaml files define literally every possible configuration option, and anything in the configuration
can be influenced via these files. We refer to this as the Hierarchical Configuration Format (HCF). This system produces a clear and
logically organized structure to cpature definitions and modifications that can be easily saved/version controlled and shared for future resuse.
A vital aspect of the imsi data hierachy is the concept of inheritance. Since many model configurations or experiments are closely
related to one another, defining them all completely would lead to much duplication. By inheriting_from a parent, configurations
only need specify their unique properties relative to that parent.
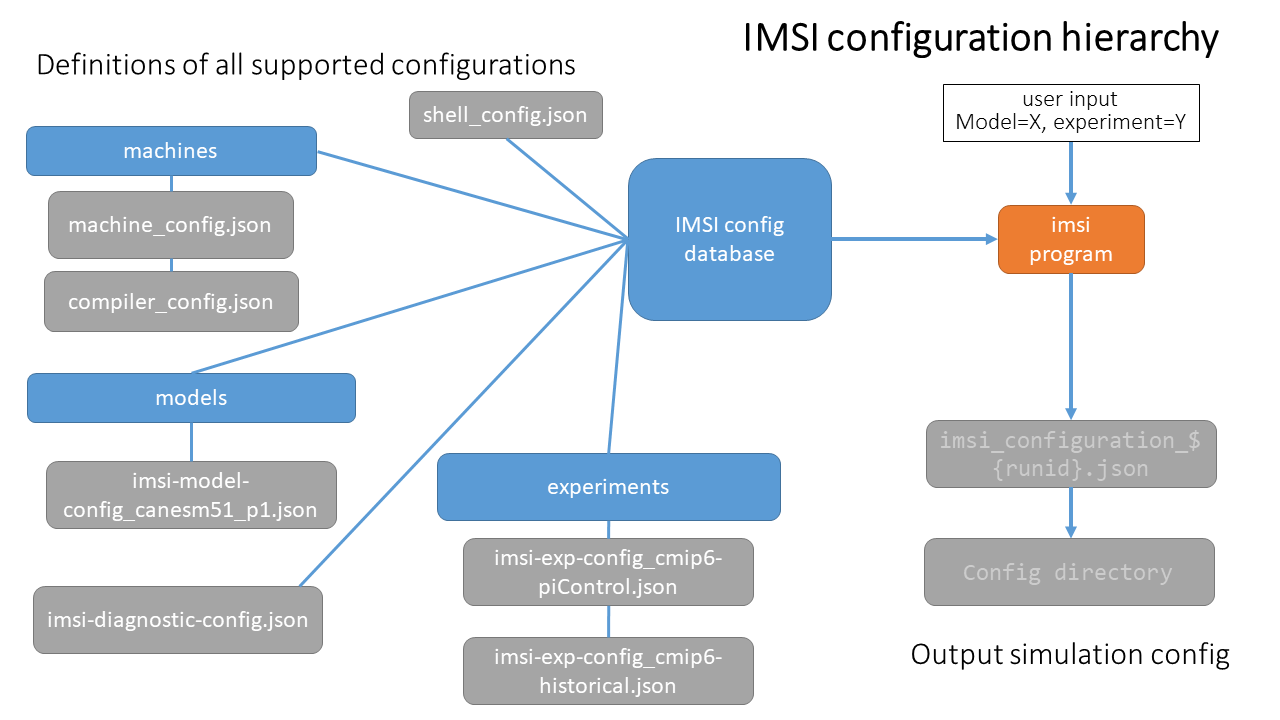
Imsi organizes the configuration in yaml files, which are easily parseable by humans and machines. However, for the most part,
downstream models and scripting do not ingest yaml files, but namelists, environment variables and so on. Hence, when imsi
applies a configuration, what it outputs are the required namelists, cppdef files, shell_parameter files, and so on. These are
largely contained within the config directory.
While users can modify these config directory files manually (and they will be used in the simulation), the issue with this
is the high rate of human error, and the fact that any applied changes will not be resuable. On the other hand if users apply
changes in the upstream yaml configurations, they are savable, resuable and easily shareable.